CNRV
关注RISC-V和Chisel以及开源IC和EDA在中国的发展
RISC-V 双周简报 (2018-05-25)
要点新闻:
- RISC-V Day Shanghai开放注册和邀请演讲者
- FireSim宣布开源
头条新闻
RISC-V Day Shanghai开放注册和邀请演讲者
RISC-V基金会在2018年有五场全球范围内的活动,而6月30日在上海复旦大学光华楼举办的RISC-V Day Shanghai你绝对不能错过,这次研讨会除了在全球领域对RISC-V有贡献的公司外,还召集了几乎所有国内在RISC-V领域有贡献的公司和个人。
群头非常希望和你们在研讨会上聊聊如何RISC-V在中国的发展,不论是技术的还是商业的。以及国内中小企业如何通过RISC-V来提高自身优势等话题。
活动的注册网址: https://tmt.knect365.com/risc-v-day-shanghai/ 或复制短链接 http://t.cn/R12WUFb
同时仍然欢迎有兴趣来做演讲的公司、研究机构或者个人提交你的演讲。演讲时长可以为25分钟、15分钟或者3分钟的poster preview。演讲提交的截止日期是5月28日。 演讲提交地址https://app.jiffyevents.com/s/fi1t292ro3或短网址 http://t.cn/R12lge0
对于活动有任何问题可以直接发邮件给Alex Guo xfguo@xfguo.org。

技术讨论
关于快速核间通信的讨论(fast hart-to-hart)
先普及一个专用名词,hart意思是硬件核心的意思。
在邮件组里有人发起了关于快速的硬件核心间通信的问题。
常见的核间通信可以大致被分为几种,传统的多核处理器中核心之间的通信和在NoC中不同Tile中Core的通信。最开始的讨论列举了各种各样的核间通信的手段,不论是FIFO还是通过一致性缓存,或者通过某些独立的硬件,甚至在多个芯片之间的通信也要被考虑进来。而收到消息的时候是否触发中断,如何处理消息队列的空和满也是要考虑的问题。
在一系列自由讨论之后,RoaLogic的Richard Herveille提出了较为普适性的提案,即通过增加3条指令来实现这个功能,而这3条指令被设计成尽可能和具体的硬件实现无关。
If inter-processor communication is FIFO based and we use special instructions, would that solve most of the blocking objections?
A hart sends a message to another hart using a send-message instruction. This gets stored into a dedicated (hardware) FIFO belonging to that hart.
The receiving hart gets interrupted when there’s a message for it. These harts could be either in the same core, chip, or even off-chip.
The sending hart’s command fails (traps?) when the receiver’s message buffer (FIFO) is full, which (most likely) indicates that the receiver is stuck.
The actual communication channel can/should be implementation dependent; direct connections would be low-latency, whereas messages send via the NOC might have higher latency. Messages sent off chip would, obviously, have the highest latency.
Does that mean we’d need 3 instructions (assuming we’re using dedicated instructions)?
- MSTORE: message send; send message to a target hart) and store it in its message-buffer. Traps when target buffer is full.
- MLOAD: message load; load message from local message buffer. Traps when buffer is empty.
- MFLUSH(?): flush local buffer
后续的进一步讨论请移步邮件列表~
Link: ML:fast hart-to-hart communication?
为什么RISC-V定义的PPN和VPN位数不一致
在RISC-V的特权指令级定义中,一个内存页的大小为4KB,地址偏移量为12比特,但是在RV32系统中,一个页表项(VPN和PPN)却只有10比特。这是因为一个PTE(page table entry)的大小为32比特,其地址是4B对齐的,没有必要记录最低的2比特PTE地址。 同时,VPN[1]为10比特,但是PPN[1]却为12比特。这是为了在32位系统中支持最高64GB(34比特物理地址)的内存。 一个虚拟地址空间的最大大小为4GB,但是通过将10位的VPN[1]映射到12位的PPN[1]就可以实现多个虚拟地址空间合用64GB实际内存。
Link: sw-dev上的讨论: 链接
自由的RISC-V (Libre RISC-V)?
Luke Kenneth Casson Leighton 和 Jacob Bachmeyer 想成立一个 Libre RISC-V 的组织来维护自由的RISC-V,以保证RISC-V的logo只被用于开放系统。
Jacob Bachmeyer: Also, some organization needs to be the “face” of the approach and protect the “open general-purpose RISC-V” logo to ensure that it is only used on systems that actually meet the purpose. I was hoping that the Libre RISC-V group might be interested in the idea, if the RISC-V Foundation does not itself take that role.
然而,这个假设和RISC-V的初衷是违背的。 RISC-V是RISC-V基金会的商标。只要符合RISC-V标准,即使不是会员的非商业使用也可以自由使用该商标。
Krste: RISC-V is a trademark of the Foundation. Non-commercial use is granted to non-members for systems that follow the RISC-V standards.
最初加州伯克利的RISC指令集现在已经算进入公有领域,可以被免费使用。但是使用这些指令集的系统不能直接被称作为RISC-V系统,除非该系统符合RISC-V标准。 如果Libre RISC-V不符合上面的原则,就不应该是被称为RISC-V。
The RISC ISA that was originally designed at Berkeley is effectively public domain, and derivatives can be developed and used freely. But they cannot be called RISC-V, or use RISC-V in their name, except if they follow Foundation guidelines. If “Libre RISC-V” is not following the guidelines, then the project should change it’s name.
关于RISC-V名字的使用规则,是为了防止歧义、社区分散和商标劫持。
The policy around the name was set up to avoid confusion, fragmentation, and/or hijacking.
我(Krste)正式地说,RISC-V基金会致力于推广最广泛的软件多样性,并不限制RISC-V的使用。
For the record, the Foundation is interested in having the largest possible variety of software run on RISC-V, and not in restricting uses of RISC-V.
一个目的是使能彻底免费和开放的硬件设计,不隐藏任何软件和固件。另一个目的则是使能彻底封闭的硬件设计。 这两个目的并不矛盾。这两个用途对在不同场景下维护安全和自由都至关重要。
One goal is to enable completely free and open hardware designs, with no hidden software or firmware. Another is to enable completely locked-down hardware designs. These goals are not contradictory. Both are valuable for preserving freedoms and security in different scenarios.
Link: isa-dev上的讨论: 链接
用 LLVM 编译 RISC-V 代码(Building RISC code with llvm)
Gnanasekar R 发现是使用自己编译的发布版模式的 LLVM 无法编译出带有压缩指令集的代码,但他使用的 GCC 可以。
Bruce Hoult: LLVM 的优势:易于修改,所以是人们在 RISC-V CPU 中实现自定义扩展指令的编译器的较好选择,并可能成为第一个支持新的标准扩展指令集的编译器。最新的 Low RISC LLVM汇编器暂不支持压缩指令集,可以通过使用 ‘-S’ 参数生成汇编代码的方式证明。
Alex Bradbury(lowRISC): 最新的 upstream LLVM 已经支持了压缩指令集,并提供了多种验证步骤。 但是同时需要一个补丁 被 upstream 接受以解决 LLVM 无法找到头文件的问题。
Luke Kenneth Casson Leighton: 提醒编译调试模式 LLVM 的工程师: ld 需要将所有工作目标文件放入内存,可能导致系统崩溃,即使是超出内存空间一点点也会让编译进程的执行变得极其缓慢。Bruce Hoult 给出了可完成调试模式编译所对应的系统配置建议。Jim Wilson 告知 ld 将需要的所有工作目标文件放入内存的原因: 优化编译效率,尽量避免频繁使用系统IO读取文件。
Links:
- Upstream LLVM: LLVM and Clang repositories hosted by llvm.org
- sw-dev上的讨论: 链接
Sv39系统中一个被选中(taken)分支上的非法目标地址的指令页错误(Instruction page fault for an illegal target address of Sv39 from a taken branch)
chuanhua.chang 提出: 在最新的特权体系结构标准中提到: 指令取指地址和载入(Load)和存储(Store)的有效地址是 64 位, 63-39 位必须与第 38 位相同, 否则将产生一个页错误。 在最新的 ISA 标准中: 当发生一个条件分支或者无条件跳转,若目标地址不是4字节对齐时, 将产生一个指令地址不对齐异常。
那么,一个被选中(taken)分支上的非地址对齐的指令页错误将在这个分支指令上产生一个指令地址不对齐异常, 再者(在Sv39系统中)一个被选中(taken)分支上的非法地址,页错误在取指阶段将在目标地址上产生还是在分支指令上产生?
建议设置一个在源指令(而非目标指令)中检测非法目标地址的基本原则,便于调试。Krste(Asanovic)曾经提到过:可以在分支指令中检测非对齐地址。但为何不是Sv39非法地址而是非对齐地址? 我们仅需要的是一个针对这两个异常的优先级。
Tommy Thorn: 应该是先被触发的那个中断,并最好去 riscv-test 查找有没有相应的测试用例,否则应该创建一个。
Andrew Waterman: 同意 Tommy Thorn 的观点,并补充道:为尽可能简单方便地探测异常,相对于探测虚拟地址是否合法有效,探测非对齐则较为容易。 虽然 ISA 设计选择有点不一致,但也很务实。
Jacob Bachmeyer: 同时应该注意的是:指令非对齐、指令访问错误和指令页错误在 RISC-V 中都是不同的异常。 使得非法指令地址的取指异常是发生在取指阶段而不是放入 PC 阶段的决定也出于安全上的考虑(xRET)。可以参考”Intel SYSRET bug”: RedHat Bugzilla, Xen Blog, osdev Wiki
Link: isa-dev上的讨论: 链接
构建RISC-V的llvm编译器的时候崩溃(LLVM compiler crash while building for riscv)
Gnanasekar R 发现在构建RISC-V的llvm编译器的手崩溃. 从报错信息来看来看,除了“collect2: fatal error: ld terminated with signal 9 [Killed]”没有真正有用的出错信息。
因为是在ubuntu 16上编译,而在linux系统 signal 9的定义是 SIGKILL (确认杀死) 当用户通过kill -9命令向进程发送信号时,可靠的终止进程,从而可以判断是系统主动发出了杀死进程的信号,所以最有可能的是系统内存资源不够,导致OOM(Out Of Memory Killer)。
讨论最后,Bruce Hoult 给出了内存和编译参数的一些参看:
LLVM debug builds currently need a minimum of about 10 GB of disk cache for reasonable performance, plus 6 GB per simultaneous program link (i.e. the number of (hyperthreading) cores in your machine, by default).
当前RISC-V的llvm编译器debug版本,基础需要10GB,每个链接进程需要6GB,链接进程数默认跟CPU核数一致。但是可以通过LLVM_PARALL_LINK_JOBS宏来控制。
- 内存16G, -DLLVM_PARALL_LINK_JOBS=1
- 内存32G, -DLLVM_PARALL_LINK_JOBS=3
- 内存48G, -DLLVM_PARALL_LINK_JOBS=8
- 内存72G, -DLLVM_PARALL_LINK_JOBS=10
- 内存超过128+GB, -DLLVM_PARALL_LINK_JOBS=无限制
Link: RISC-V SW Dev讨论 链接
代码更新
FireSim宣布开源
FireSim能够在亚马逊F1云上通过FPGA来加速周期精确的基于rocket-chip的始终速率从十几MHz到数百MHz级别的仿真。(150MHz下的4核仿真,或者大约10MHz下的1024或4096个节点的使用数据中心的网络通信和接近16TB内存进行的仿真)
Github repo: https://github.com/firesim/firesim Docs: https://docs.fires.im
在这一版的Release中其支持两个Case:
- 单节点并行仿真(不需要仿真网络):跑一遍SPECInt 2017大约需要一天的时间,也可以boot Fedora。
- 数据中心/集群上的仿真:通过以太网连接的、指令周期精确的超多核心的仿真。
- ISCA 2018 论文 http://t.cn/R129Xzz
- ISCA 2018 lightning talk: http://y2u.be/4XwoSe5c8lY
- 项目中的脚步和文档可以在云上验证。 http://t.cn/R129HQw
有人问和gem5的关系:
The end goal is similar to gem5 - ultimately we want to collect performance results for some hardware design - but the approaches are different.
In FireSim, the simulator is automatically derived from the RTL that describes a hardware design, in this case Rocket Chip (although the methodology is not specific to Rocket Chip). So the simulator “implements” the RISC-V ISA as an artifact of the fact that it is modeling Rocket Cores (that implement RISC-V) on the FPGA. Similarly, we can plug-in “BOOM Chips” and model those without extra effort, since the simulation is derived from the RTL (this is a WIP, should show up on a branch soon).
With our automation, we’re aiming to achieve the ease-of-use of gem5, but with the performance of FPGA-accelerated simulation, all while being derived from real hardware implementations rather than handwritten abstract-models.
点评:群头必须告诉你的是,未来半导体公司必须开始重视云计算能给我们的生产力所带来的改进,从AWS F1到国内云计算厂商都开始部署FPGA云,尽管这些云99%都不是用来做IC仿真加速或者验证的,但是正式因为有了其他99%的应用,才能有效的拉低云上FPGA的价格,从而有效的降低研发成本和提高生产力,我认为这也是Agile Hardware Developtment中重要的一个环节。
Link: Google Group讨论
rocket-chip更新详细的gdb调试指南
来自法国的 Noureddine Ait Said (@noureddine-as) 在 Rocket Chip 的 README.md 增加了关于使用 GDB 调试 emulator 的文档。
该文档描述了如何以跟 Spike 一样的方式使用 GDB 去调试运行在 Rocket Chip (使用 verilator)的仿真器上。
Links:
实用资料
Chisel教程(Chisel tutorials)
Martin Schoeberl 在chisel-users讨论组中提到要欧洲推广Chisel, 并向两个会议提交了两个半天的教程提案,希望在教程中有一些动手实验。 Edward Wang 和 Yaman Umuroglu 都推荐了generator-bootcamp,generator-bootcamp 是一个基于jupyter的交互式Chisel教程。
通过generator-bootcamp能够在阅读教程同时编写scala并运行输出,及时查看输出结果。同时generator-bootcamp的环境安装简单,能够跨平台运行。
安装方法:
运行效果:
-
generator-bootcamp教程目录
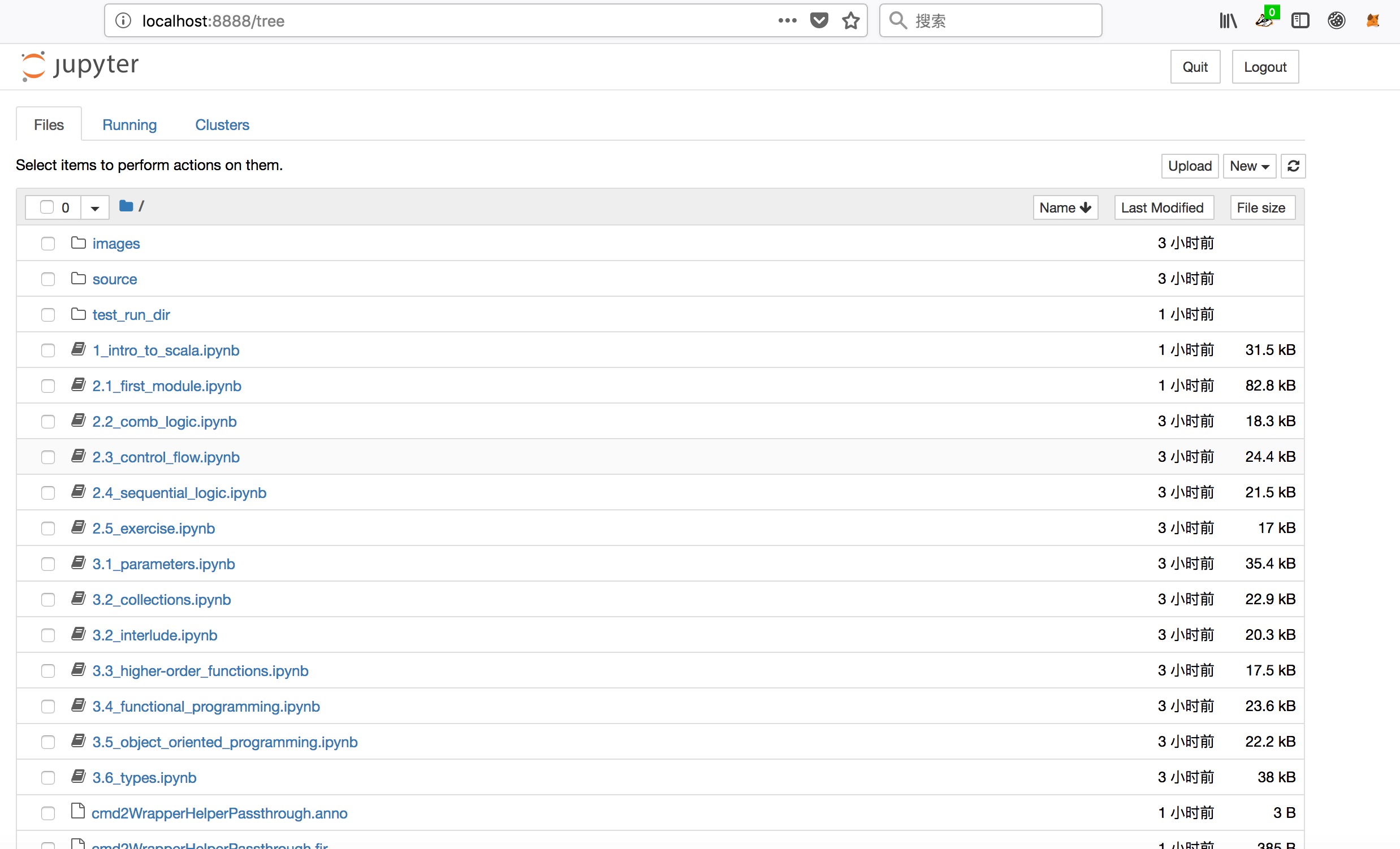
-
进入generator-bootcamp教程详情页
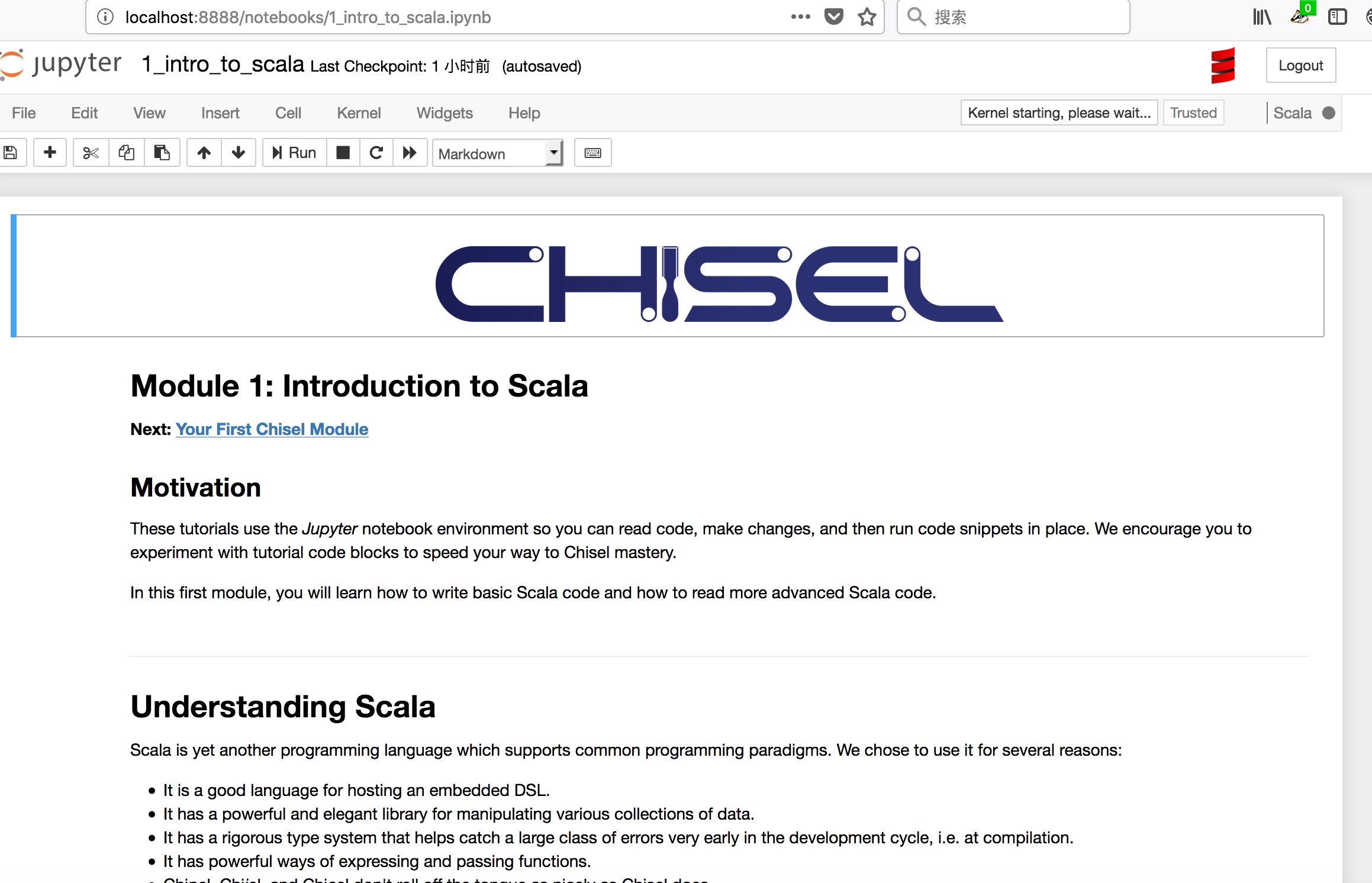
-
jupyter运行Chisel效果
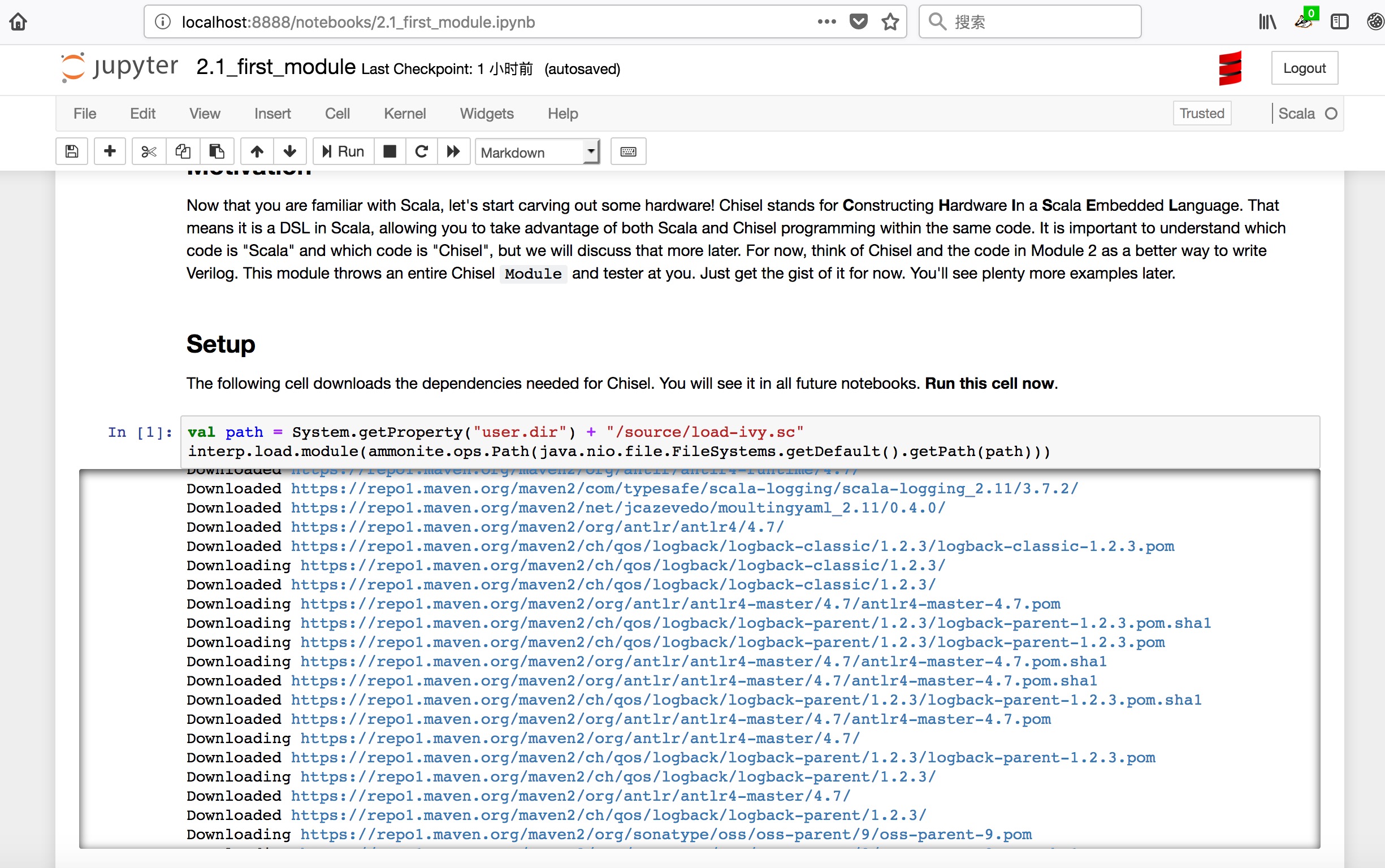
-
Chisel效果Verilog效果
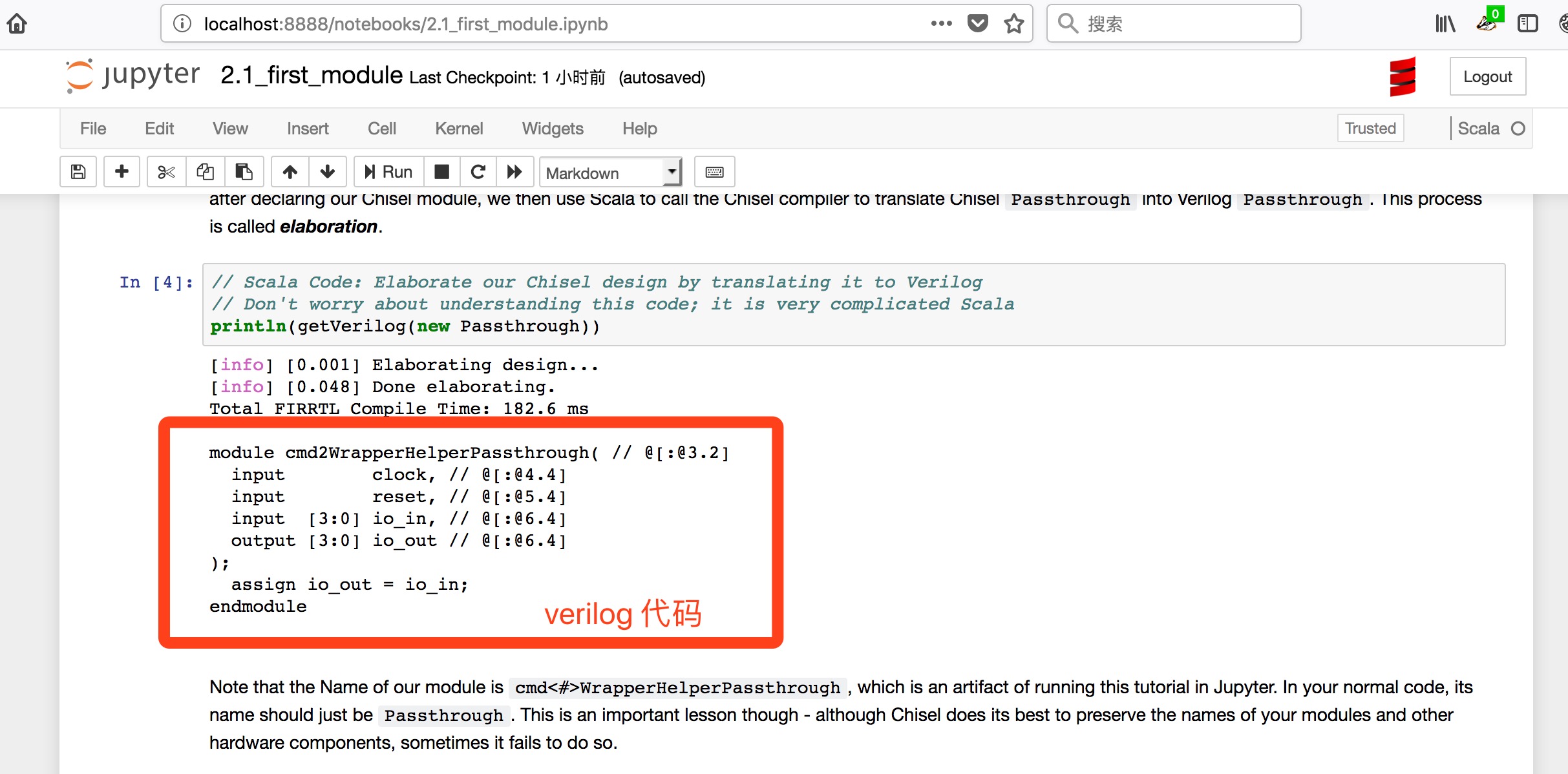
Chisel是由伯克利大学发布的一种开源硬件构建语言,建立在Scala语言之上,是Scala特定领域语言的一个应用,具有高度参数化的生成器(highly parameterized generators),可以支持高级硬件设计。Chisel是是一个纯scala语言的库,而scala是一门多范式(multi-paradigm)的编程语言,设计初衷是要集成面向对象编程和函数式编程的各种特性,Scala运行在Java虚拟机上,并兼容现有的Java程序。所以可以很好的运行在windows,linux和macos系统上。
对于英文最好的教程可能是官方wiki, CSDN有一个不错偏实践操作的中文教程
Links:
- chisel-users上的讨论:链接
- Github Repo: https://github.com/ucb-bar/generator-bootcamp
行业视角
John Hannessy和David Patterson接受Recode的采访
两位图灵奖获得者最近接受了Recode的创始人Kara Swisher的采访。整篇访谈非常值得完整的聆听,当然在这里我们只摘取和RISC-V相关的部分。
DP: That’s the one that I’m particularly interested in, and this, I think I talked about earlier with RISC-V, this open-source instruction set.
In the past, you know, we’ve had to wait for Intel. We have to beg Intel to make a change before we can do anything. Now we don’t have to beg anybody. We can jump in there, come up, try ideas, put them online through these field programmable gate arrays, and see if they work. And not only that, you don’t have to work for Intel or ARM. Anybody in the world can do this. So we could see this potentially rapid acceleration of innovation around security with architecture and software systems. We need to get better at this, and I can imagine this path working. And so yeah, that’s what I think that’s a really exciting thing to work on.
Link: Full transcript: Dave Patterson and John Hennessy on Recode Decode
Rupert Baines的巴塞罗那研讨会观后感
Rupert Baines是UltraSoC的CEO,一位业界老兵。他在Eembedded Computing上发表了自己最近参加完巴塞罗那会议之后的观后感。
Between the 6th Workshop in Shanghai in May 2017 and the 8th Workshop in Barcelona, the industry has moved from discussing the fundamentals of the ecosystem, to making solid choices about implementation and security. We’re now starting to see and hear about products that are well down the road in development. Several groups brought RISC-V based systems to Barcelona, running various flavors of Linux—the RISC-V desktop PC is now a reality, including multi-core systems.
…
With all this positive news, why am I still uneasy? With any new technology, the question of “Are we there yet?” will always come up. Many technologies don’t fulfill their potential, so the question is valid. Where is RISC-V then, in terms of development and adoption? Is it living up to the hype? There’s a large gap between a great idea and commercial success.
I don’t think RISC-V has quite crossed the chasm yet. There’s still a feel of early adopters and evangelists, and people wanting to see it move to the next stage. They want to see commitment and designs from more companies, which is why people were clamoring to see working demos. We’re getting there, and things are moving quickly. But we do need the industry to work harder to make it all happen. We’re now seeing the early adopters.
Links:
zGlue的System-on-a-Chip
zGlue是一家初创公司,试图通过封装技术来将诸如CPU、传感器等不同的小芯片集成在一起来制造面向IoT的小芯片(chiplet)。
在TechCrunch的采访中,zGlue的创始人Ming Zhang提到了他对RISC-V的看法。
Zhang, too, said RISC-V offers some potential, especially in its own scope. “RISC-V is a great tool to build small, fast, and low power IoT applications,” he said. “The nature of open source makes it more available to more people. We welcome and embrace RISC-V to join the family of ‘MCU’ chiplets supported by our technology.”
Links: zGlue launches a configurable system-on-a-chip to help developers implement customized chipsets
市场相关
IPnest的最新报告显示去年ARM在CPU IP上的收入同比下滑
IPnest在SemiWiki上的最新调查显示,2017年整个行业Desgin IP的收入增长了大约12.4%。ARM依然坐头把交椅,但是其收入同比去年减少了6.8%。
另一方面,RISC-V开始展现其强劲的势头,预计2019年结果便得以揭晓。
ARM is obviously #1 in the CPU category, and will probably keep this position for a long time due to the royalty mechanism. Nevertheless, we can see that ARM CPU IP license revenue has declined by 6.8% YoY, more than compensated by the royalty revenue growing by 17.8%. The reasons may be multiple. After the ARM acquisition by SoftBank, the accounting policy was changed creating what Eric calls an “artifact”. However, in my opinion we are starting to see the impact of RISC-V becoming a credible alternative to the ARM CPU hegemony. The 2019 Design IP report should confirm this.
Links:
AndesTech和SiFive在上海同时推广RISC-V
5月17日,在上海的同一家酒店,SiFive和AndesTech各自举办了其技术推广研讨会,吸引了不少国内的爱好者参加。
Links:
暴走事件
六月
- 2nd CARRV 第二次CARRV workshop(Computer Architecture Research with RISC-V ) 将在6月2日和ISCA 2018共同举办。
- RISC-V Day Shanghai, 2018年6月30日 https://tmt.knect365.com/risc-v-day-shanghai/
- 2018年7月1日,也就是RISC-V Day Shanghai的后一天会有HelloLLVM的线下聚会活动,具体地点和时间还未确定,何不一波流来上海玩一把?
七月
十月
- RISC-V Day Tokyo (mid-October TBD)
十二月
招聘简讯
CNRV提供为行业公司提供公益性质的一句话的招聘信息发布,若有任何体系结构、IC设计、软件开发的招聘信息,欢迎联系我们!
整理编集: 宋威、黄柏玮、汪平、林容威、傅炜、巍巍、郭雄飞
欢迎关注微信公众号CNRV,接收最新最时尚的RISC-V讯息!


本作品采用知识共享署名-非商业性使用-相同方式共享 3.0 中国大陆许可协议进行许可。