CNRV
关注RISC-V和Chisel以及开源IC和EDA在中国的发展
RISC-V 双周简报 (2017-08-17)
RV新闻
SiFive任命Naveed Sherwani新CEO
SiFive任命了曾任职于Intel、Brite Semiconductor和Open Silicon的Naveed Sherwani为其新的CEO。
…
“The industry needs to change if it is to survive,” he said in the email. “If we don’t do anything, we will end up like the steel industry. When SiFive asked me to join, I picked 40 people from my network and called them. Two things happened: They all knew about RISC-V; second, they all agreed the concept had merit and tremendous potential. In my mind, SiFive, founded by the inventors of RISC-V, has the best chance to make this revolution happen.”
Link: http://t.cn/RCAB8oI
Bristol startup designs security chip
布里斯托一家创业公司(Cerberus Security Labs)在其设计的安全芯片中使用了开源的RISC-V处理器
The chip design uses the RISC-V open source core and a custom encryption and key management unit. The RISC-V technology is gaining popularity as there is no licensing fee to companies such as ARM or MIPS.
Link: http://t.cn/RCArmZc
Gen-Z Points to New Memories
WD described a similar concept, showing a sea of low gate-count processors using an open instruction set surrounding a persistent memory. The company has announced it will deliver a ReRAM before 2020 and is supporting both the Gen-Z interconnect and the RISC-V ISA.
我们能够看到开源处理器在某种程度上让相关行业的创新变得容易了。
Link: http://t.cn/RCAeSUC
以色列关于RISC-V的Genpro计划
以色列的 Israel Innovation Authority 最近公布了 2018 年 关于RISC-V的Genpro计划。希望能建立一个以RISC-V为基础的运算平台。
GenPro: Developing an advanced processing platform which is rapid, efficient and independent, based on the RISC-V core. This unique platform will enable members of the consortium to make optimal use of the code generated in the processing system in accordance with the singular needs of each company, while cooperating on the development and efficient use of resources. The goal of the entrepreneurs is to develop software and hardware technology based on the RISC-V processor’s open core, which enables the achievement of improved performance, implementing hardware accelerators to the processor, use of multiple cores and support of a range of additional abilities, while reducing consumption and the required silicon surface. The group members are aiming to jointly develop the processing platform. The kick off meeting will be held on Sunday, August 13, 2017.
Link: http://t.cn/RCAr5tj
CNRV/RISCV-FPU
王逵同学最近开源了他设计的浮点运算部件,包括加法器、乘法器、触发器和平方根。此项目未来将在https://github.com/cnrv/RISCV-FPU中进行开发,希望最终可以为RISCV的各种开源和商业实现提供高质量的FPU实现,满足这些特征:单精双精共同数据通路以减小面积,采用recoded浮点数表示以实现高主频,乘法器和加法器分离且均为3周期latency。同时此项目还具有这些特征:基于Systemverilog,代码易读易懂(可用于教学),位宽可配置(可用于其它场合)。欢迎更多的开发者加入进来。
PULPino添加新成员
PULPino最近的更新推出了面向微型系统的两级流水线微处理器Zero-riscy。 现在PULPino支持4种不同的配置,从复杂到简单依次为:
- RI5CY+FPU:4级流水线的RI5CY,支持RV32-IMC,PULP的DSP扩展vector指令,和最新添加的IEEE-754单精度浮点运算单元。
- RICY:4级流水线的RI5CY,支持RV32-IMC和PULP的DSP扩展vector指令。
- Zero-riscy:2级流水线的小核,支持RV32-IMC,无DSP扩展。
- Micro-riscy:2级流水线的微小核,支持RV32-EC。
详细信息参见PULPino官网:http://www.pulp-platform.org/
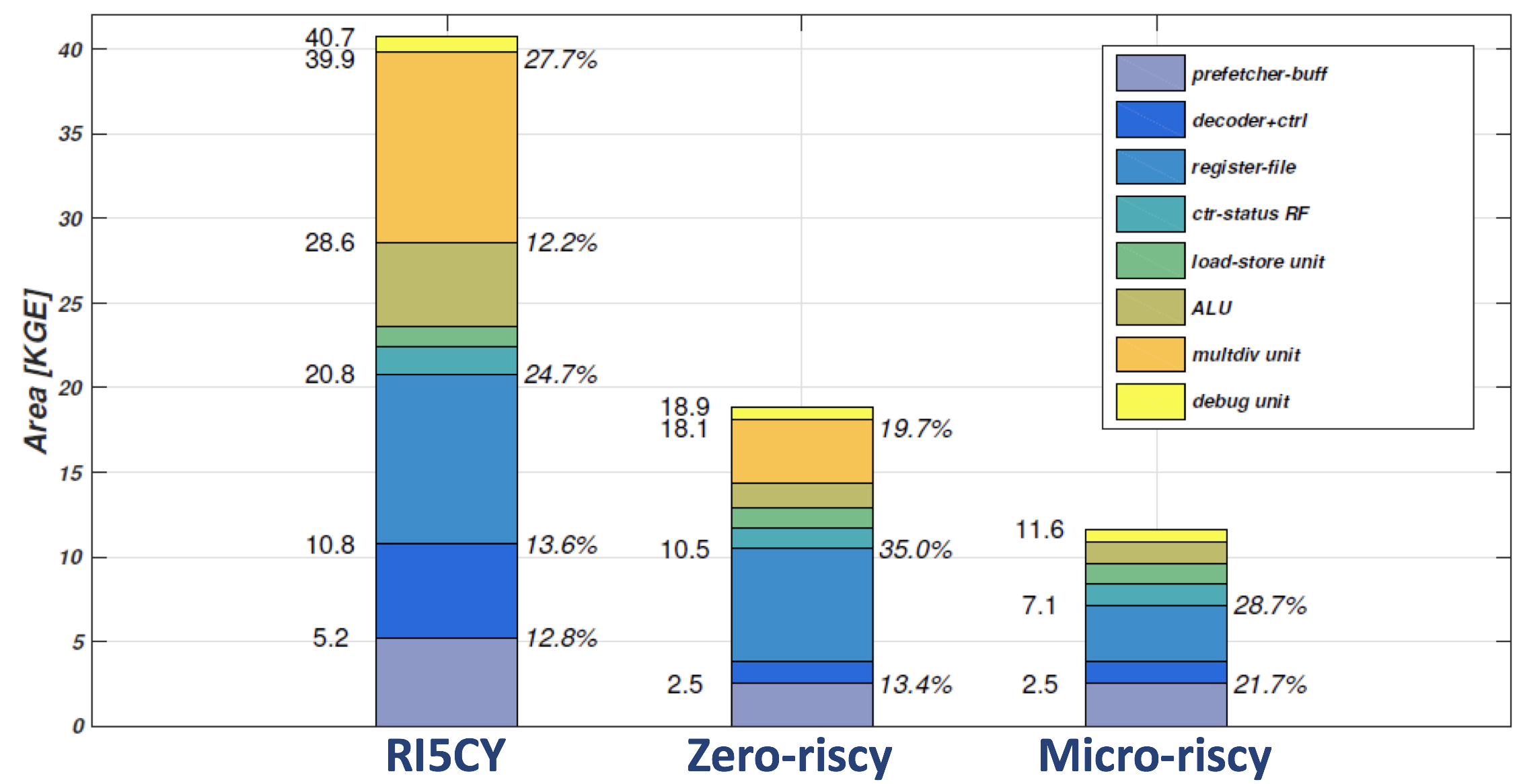
不同处理器之间面积的比较(图片来源于PULPino官网)
BOOM发布第2版
BOOM是加州伯克利大学Christopher Celio设计的乱序RISC-V处理器。最近他刚刚发布了第二版的BOOM处理器。
更新列表:
- 提高了综合性能
- 指令发送窗口拆分为ALU、内存操作和浮点运算三个,以提高发送效率。
- 同样的,物理寄存器也被拆分为整数和浮点数部分。
- 添加issue-select和register-read流水线级。
- 重命名被拆分为两级。
- BOOM使用自己的BTB模块(独立于原有Rocket BTB)
- 使用新的BTB和指令解码信息加强分支预测。
- 优化SRAM使用方式。
- 提供了一个使用Blackbox来使用专有设计替换Chisel寄存器文件的例子。
Chris Celio的发布公告:https://goo.gl/MyVR4k
- BOOMv1 代码地址: https://git.io/v7xxv
- BOOMv2 代码地址: master分支或者 https://git.io/v7xxk
ORConf 2017会议日程公布
ORConf会议原本是OpenRISC开源处理器的年度开发者大会。最近两年会议讨论内容被逐步放宽,演变成开源硬件社区的年度大会,每年初秋在欧洲举行。 今年的会议将于9月8-10日于英国Hebden Bridge小镇举行。 会议预定日程刚刚公布,其中有一些很有意思的报告, 比如PULP的第二版发布,开源硬件社区自己的持续测试(CI)平台LibreCores CI, 新的开源硬件代码仓库(repo)LibreCores.org, VHDL的UVM验证模型UVVM, 基于lowRISC的串行一致性(Sequential Consistency)研究,等等。
会议网站: https://orconf.org/
RV32E工具链支持
GNU工具链针对RV32E的相关PR于上周二更新(RISC-V GCC PR #77), 希望于在八月底完成对RISC-V GNU工具链的完整支持。RV32E是RISC-V中针对嵌入式平台制定的指令集。 与RV32I的主要差异在于RV32E仅使用16个寄存器以满足嵌入式平台对于功耗与面积成本的需求, 并进一步限定RV32E仅可支持M,A和C扩展指令集。
除了指令集扩展上的差异外,RV32E与RV32I的ABI(Application Binary Interface)也有部份差异。 例如RV32I中可用a0-a7等八个寄存器传递参数,在RV32E中则只有a0-a5可用来传递参数。 并且针对嵌入式平台的使用情境,栈的对齐要求也从原本的16字节对齐变成仅要求4字节对齐, 以此来缩减内存使用。
coreboot for HiFive1 (Hello RISC-V world!)
coreboot的前生是LinuxBIOS,是一个自由固件的实现,目前主要支持x86,对ARM也有一定的支持,对于RISC-V的支持社区还在努力(可参见coreboot代码分析),近日HardenedLinux社区公开了一个针对HiFive1的coreboot示例,由于RAM资源限制目前只能开发一些简单的功能,coreboot框架并不适合microcontroller甚至小型GNU/Linux嵌入式平台,或许RV64才是其未来的归宿。
Sodor更新至Priv spec 1.10
用于教学用的RISC-V简单核Sodor被更新至Priv spec 1.10, Chisel 3和Debug spec 0.13。感谢FOSSi Fundation的GSoC学生Kritik Bhimani。
Sodor的地址: https://git.io/v7Kld
RISCVEMU
由Fabrice Bellard维护的RISC-V Linux emulator: RISCVEMU现在已经支持32/64位Linux和基于VirtIO的多种外设。 并且,他还提供了可在浏览器中运行的RISC-V Linux: JSLinux。
详细信息参见:https://bellard.org/riscvemu/ 和 https://bellard.org/jslinux/
Apace Mynewt for Hifive1
Hifive1的板子现在也支援Apache Mynewt这个嵌入式操作系统了。
技术讨论
基于gp寄存器的链接时优化机制
由于RISC-V跳转指令中立即数的长度限制,超过4K距离的长跳转需要由两条指令完成。
针对这种长跳转,可以将gp寄存器指向使用比较频繁的4k代码空间,然后用基于gp的间接跳转替换基于PC的跳转,仍然使用1条指令。
更好的是,这种替换可以在链接时自动完成。对于使用newlib的程序,gp一般设为.sdata + 0x800.
具体讨论参见:
- Relaxation: https://goo.gl/YCiXuh
- Global Pointer: https://git.io/v7VqV
代码更新
Release完成之前禁止Acquire
Rocket-chip的PR #955修复了一个Acquire/Release的顺序错误。这个错误非常经典,些惊讶于这个错误怎么最近才发现,值得说一说。
首先解释Acquire和Release,这两个是TileLink总线上两种报文,Acquire一般由L1 D$发给L2 coherence hub,使用A通道,表示L1 D$希望获取一个缓存块或更新其对该缓存块的权利。Release一般也由L1 D$发给L2 coherence hub,使用C通道,表示L1 D$回写一个缓存块。假设处理器希望读写缓存块B,但是L1 D$没有B,需要向coherence hub读取。为了读取B,L1 D$需要置换掉已被改写的缓存块A。Rocket处理器为了提高吞吐率和减小控制逻辑,多个missing handler共享一个回写器,回写A与读取B可能同时发生。可是如果B已经读取到,然而A却都在了回写器,直接将B写入L1 D$就导致A的数据丢失!所以将B写入L1 D$必须发生在A被回写器读取甚至写回L2之后!这个PR 955 就是在限制B的Acquire只能发生在A的Release之后。
具体参见Rocket-chip的PR #955 https://git.io/v7xGW:
修正Rocket流水线的优先转置错误
优先转置(priority inversion)是指高优先级的线程间接地被低优先级的线程抢断而发生优先级错位。 最近,Andrew在Rocket的浮点运算流水线发现了一个类似的问题。 当一条除法指令在Mem级被杀死(可能由于寄存器的写口不够而导致的资源冲突),刚好Exe级上又有一条除法指令,那么Exe上的后一条除法指令可能被送入除法器执行。 由于除法器不是并行的,被杀死的除法指令需要等待后一条除法指令释放除法器,而后一条除法指令等待前一条执行完毕才能释放,导致了死锁。 注意这里是浮点流水线而不是ALU流水线。这种情况的发生是由于浮点流水线允许一定程度上的乱序。 现在的解决办法是如果指令在Mem级被杀死,在Exe级的指令也会被杀死,两条指令都要被重跑。
具体参见Rocket-chip的PR #948 https://git.io/v7SfX
Rocket流水线识别RVC指令
在现在的Rocket流水线,RVC指令在进入EX级之前被扩展为正常32位指令(因为RISC-V的RVC指令和正常指令是一一对应的)。 最近的两个代码更新: 一个是将RVC指令格式加入到ID级的指令列表(Rocket-chip PR #889); 另一个是将RVC的原始指令引入流水线(Rocket-chip PR #993)。 让小编不禁猜想,也许他们要开始在Rocket里实现macro-op fusion了吧。
lowRISC修复Tag缓存并行错误
lowRISC6月份发布的新版本在频繁使用tag的情况下可能会导致tag缓存的数据丢失。其原因是多个相关的内存操作同时进行时,tag缓存未能有效线性化相关操作,导致出现了数据不一致错误,进而导致数据丢失。现在这个错误被修复。
具体参见lowRISC的PR 56: https://git.io/v7Kt1
Rocket-chip 支持对ROM使用$readmem()
一直以来,Rocket-chip生成的Verilog都不使用Verilog自带的$readmem()方法读取内存初始内容。现在终于支持对ROM使用了。仿真时参数应该是+maskromhex=%s其中%s为ROM的hex文件。
具体参见Rocket-chip的PR 912: https://git.io/v7apV
实用资料和文档
Palmer的All Aboard系列
Palmer的文章记录了要怎么让GCC使用不同的ISA和ABI。Palmer计划针对他有所涉猎的port,比如Linux和GCC,写一连串的文章。
Link: http://t.cn/RCAkkl2
行业视角
Nvidia CEO Huang: Big Data, Self-Driven Cars, Gaming the ‘Big Vectors’
I asked Huang about his company’s involvement in the chip-industry effort known as RISC-V, which is an outgrowth of the “reduced instruction-set architecture” model of computing that mostly dominates chip design.
Huang was enthusiastic about Nvidia’s decision to give technology to the open-source effort:
We designed a deep learning accelerator, the “DLA,” and it’s probably the best anyone has ever designed, and we open-sourced it. RISC-V is an open source company, and they asked us if we might work with them to put our DLA into it, and so we are going to give it to the community. How it benefits Nvidia is that the more people who receive deep learning computing, the more demand there will be for deep learning. And two, the DLA is supported by our Tensor RT, and so that’s how we extend the reach of our platform
暴走事件
八月
- RISC-V at HotChips, 20-22 August 2017 at Cupertino, California.
下礼拜的Hotchips会议将会有两场关于RISC-V的Talk,一场来自SiFive,另一场来自学术界。此外,也会有Gray Research, Microsemi, Gray Research 和 Codasip的Demo或Poster。
九月
- ORConf 2017会议将于9月8-10日于英国Hebden Bridge举行。会议网站:https://orconf.org/
- The 7th RISC-V workshop投稿截止日期:2017年9月17日。投稿网站:https://www.softconf.com/h/riscv7thwkshp/
十月
- OSDT开源开发工具大会2017(也就是原HelloGCC会议)将在10月下旬在北京举办,话题和赞助征集已经开始。话题内容包括“面向RISCV等新硬件的基础软件支持”,各位不要错过。
- 开源经济学研究-2017年年会邀请函
- RISC-V at the Linley Processor Conference, 4-5 October 2017 at Santa Clara, California.
- First Workshop on Computer Architecture Research with RISC-V (CARRV 2017), 14 October at Boston, Massachusetts, co-located with MICRO 2017.
十一月
- The 7th RISC-V workshop 2017年11月28-30日,第7届RISC-V研讨会将在美国加州Milpitas由西部数据承办。
招聘简讯
CNRV提供为行业公司提供公益性质的一句话的招聘信息发布,若有任何体系结构、IC设计、软件开发的招聘信息,欢迎联系我们!
整理编集: 宋威,郭雄飞,黄柏玮
贡献者: Shawn,Kito Cheng, 王逵
欢迎关注微信公众号CNRV,接收最新最时尚的RISC-V讯息!


本作品采用知识共享署名-非商业性使用-相同方式共享 3.0 中国大陆许可协议进行许可。